Importing content with the feeds module
Importing content with Feeds


For the Pixelite website, I want to add a block that displays content from external sources with content that could be related to the article the user is currently reading.
The first step in this process is to aggregate some content from RSS or Atom feeds. To achieve this we'll use a contrib module called feeds.
Install Feeds
Lets use Drush to install the feeds module and turn it on.
thepearson@localhost:~/git/pixelite.co.nz$ drush dl feedsand turn it on
thepearson@localhost:~/git/pixelite.co.nz$ drush en feeds feeds_ui feeds_importThis will also download, install and enable the Job Scheduler module which, at the time of this article is required for feeds.
Install Feeds image grabber
Lets also install an add-on module for feeds. The feeds image grabber (FIG) module will allow us to pull in images from the RSS/Atom feed items, so we can have nicer looking feed nodes.
thepearson@localhost:~/git/pixelite.co.nz$ drush dl feeds_imagegrabberand now enable the FIG module.
thepearson@localhost:~/git/pixelite.co.nz$ drush en feeds_imagegrabberContent types
I need to create a couple of content types. If you need a primer on creating content types I suggest you take a look at the Community Docs. The first content type we'll be creating is for defining the Atom/RSS feed sources. This will also allow us to specify multiple feed sources. This content type has only a title and a Url.
- Title
- Url
As the feeds module will automatically add a Feeds field to the content type we can get away with just creating a content type with a title field. Below is an image of the fields page after this tutorial has been completed.
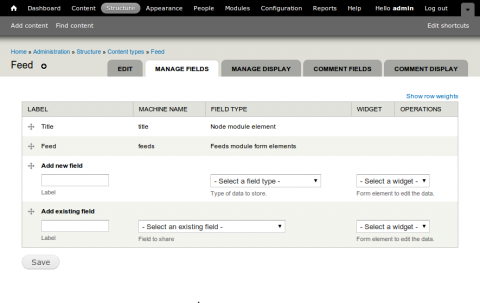
Next we will need to set up a feed item content type, this will be used as a the node type that each feed item will be imported as. I figure for this post the content type will require the following:
- Title
- Description
- URL
- Image
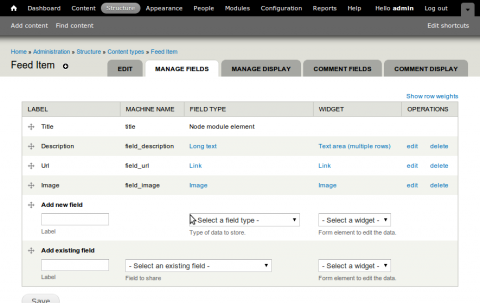
Create a feed importer
Next step. Create the feed importer. This will enable us to map feeds to our content type and will also set up importing schedule. Navigate to Structure > Feeds importers and click on the Clone operation on the Node import importer. Choose a new name and description. We should now be at the following screen.

First let's click on the Basic settings > Settings link and configure some of the more basic settings. You should be faced with the following screen.
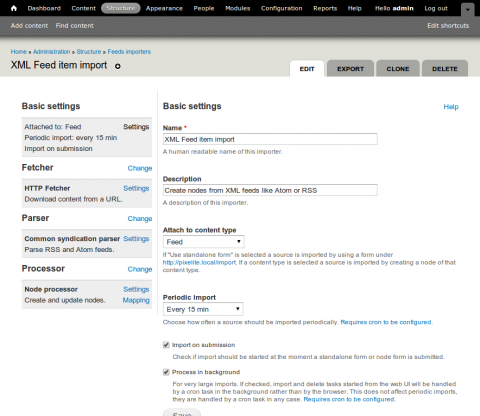
The name and description fields should be fairly self explanatory. The next field, Attach to content type allows us to define the source for our feeds, this could either be a standalone form or we can choose a source content type from the list of available content types for our site. We are going to set this to our Feed content type. Set Periodic import to Every 15 min. Check Import on submission and Process in background. Save your basic settings and click on the Change link in the Fetcher tab.
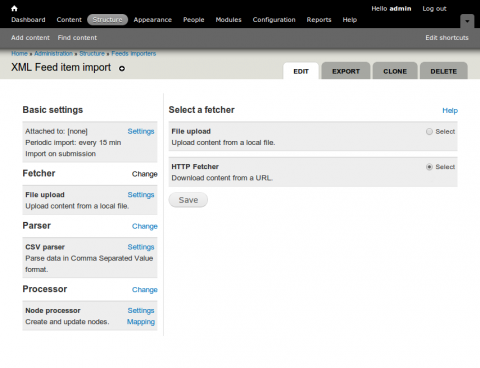
In this tab we can define how we collect the data we are trying to import. Because we are going to be importing RSS and Atom feeds we want to use the HTTP Fetcher. Select that option and click save. Now the fetcher is set to HTTP fetcher we will want to set up some default settings.
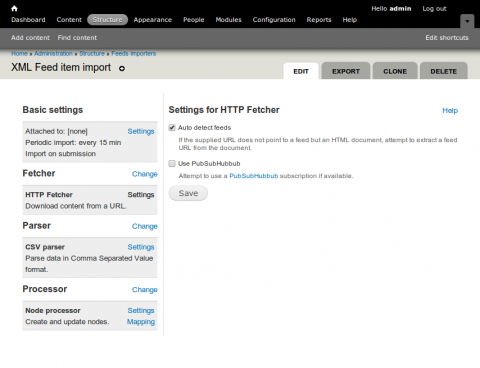
Choosing Auto detect feeds will enable some tolerance when feeds are added that link to HTML pages. The fetcher will attempt to find the feed within the document. Save that and move onto the Parser tab.
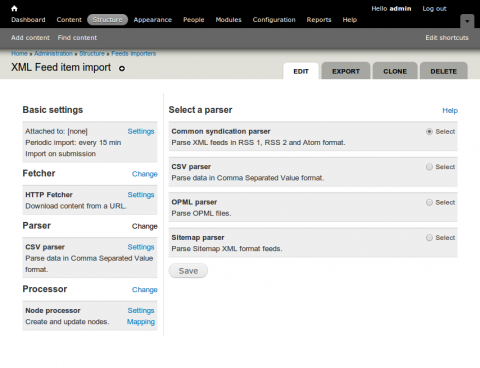
Choose the Common syndication parser, click Save. There are currently no settings to alter for the Common syndication parser so lets move on to the Processor tab and click Change.
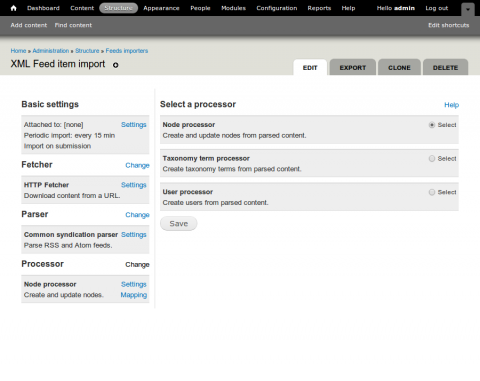
Ensure Node processor is selected, click Save and then click on Node processor > Settings.
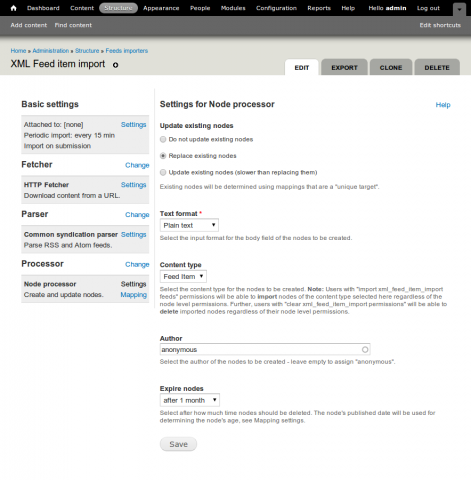
Check Replace existing nodes to replace duplicate content, Text format Plain text or Filtered HTML. Select the content type you created earlier in the Content type field. In this instance I have set the Expire nodes to after 1 month. This will remove old content after a month. Since it's only news items we''ll be aggregating we don't really need them hanging around for longer than a month. Click on the Mapping link.
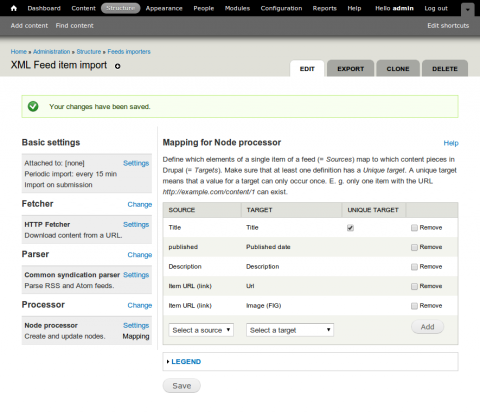
On this page we can map fields from our soure (RSS or Atom feed) to fields in our Node. Notice, we've mapped Item URL (link) twice. Once to the Url field of our content type and once to Image (FIG) the FIG link should enable us to grab images from the feed. For now our configuration is complete. Click Save.
Testing it out
Go to Content > Add content > Your source feed type Fill in a title, and add the feed url. Open up the Feeds image grabber fieldset.
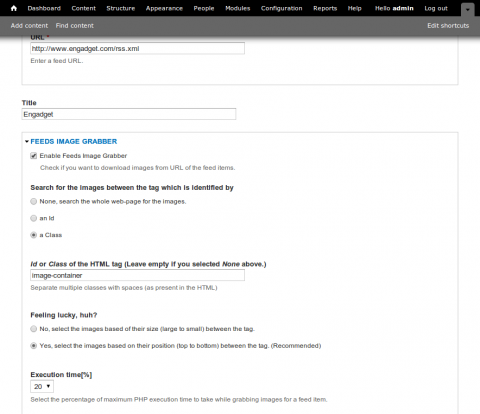
Select Enable Feeds Image Grabber. I always find it usefull to help the parser find the image I am after by specifying a class or id tags to look within. If you have any issues with grabbing images adjust the Execution time[%]. Save this content node an you should see a success message with a number of nodes imported messages. Let's validate that by going to Content and seeing what content nodes have been imported.
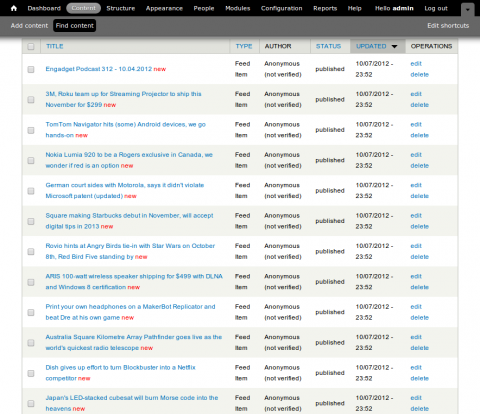
Nice, so we've got a whole bunch of imported nodes. Here is one.
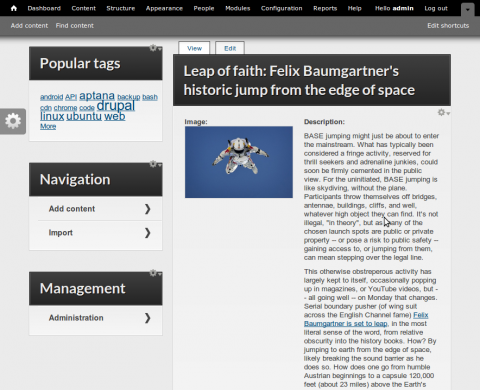
So now we have all this content being imported as nodes from other sources. In the next post, we'll do something with this content. Feel free to comment, or ask any questions.