Finding and killing long running SQL queries in AWS RDS
Occasionally we find sites that are running extremely slowly, and digging down we end up finding MySQL queries that have been running, for sometimes days or even weeks.


Occasionally, we find sites that are running extremely slowly, and digging down we end up finding MySQL queries that have been running for sometimes days, or even weeks 😱.
These stuck queries end up consuming resources, here you can see performance insights in AWS RDS, and the impact of having 3 stuck SQL queries on a database cluster with only 2 vCPU - an r5.large.
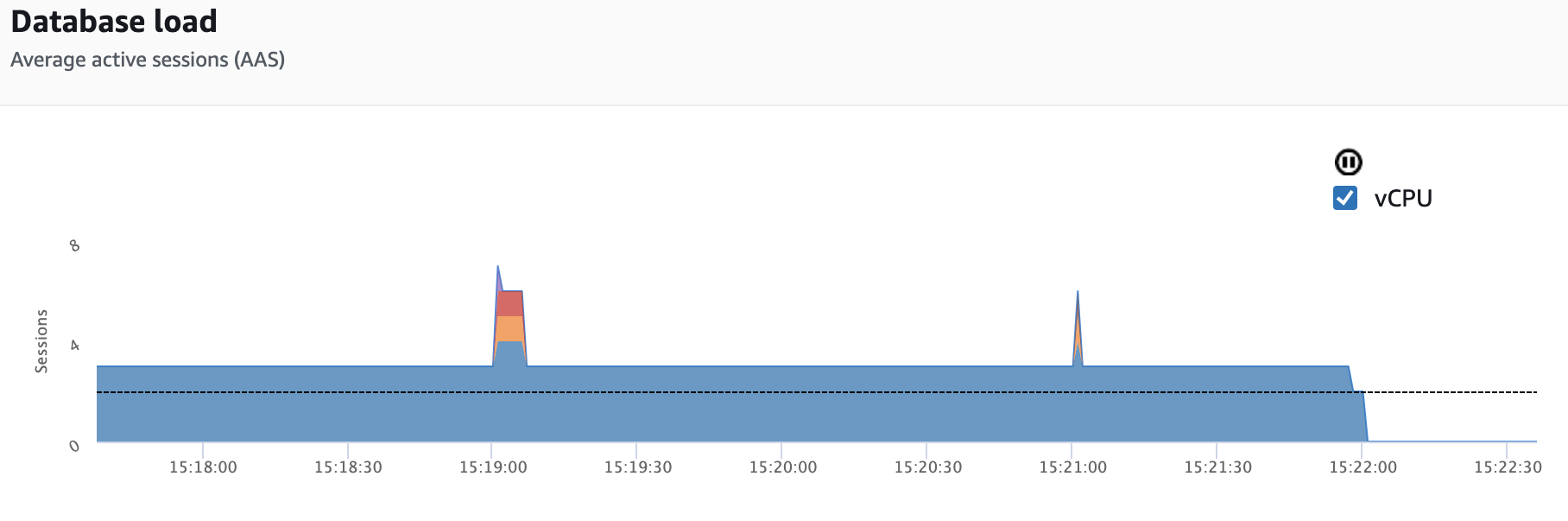
This will noticeably slow down your SQL queries (as essentially all vCPUs are tied up with existing threads).
How to find the stuck queries
The easiest way to find stuck queries is to send the following query to your database
SHOW FULL PROCESSLIST;This will list out all the queries, what user executed them and when they were first issued.
In the case above, the query looked like a cache related query for a Drupal site, and the query was stuck in a sending data state.
SELECT COUNT(*) FROM cache_advagg, cache_bootstrap, cache_config, cache_container, cache_data, cache_default, cache_discovery
Most likely the queries became hung when someone was rebuilding the Drupal cache, at the same time re-importing the database. This is not definite, but it is my best guess at the moment, based on the 3 times this has happened in the past.
How to manually kill the stuck queries in AWS RDS MySQL
If you ever find threads stuck in state sending data that will never complete, you will need to kill those queries. Note, this can cause you to corrupt a database if there are ongoing non-SELECT based queries (so execute with caution). In this example the MySQL username is drupal.
SELECT CONCAT('CALL mysql.rds_kill(',id,');')
FROM information_schema.processlist
WHERE user='drupal'This will produce a list of SQL statements to execute to kill all queries by this user.
CALL mysql.rds_kill(18047573);
CALL mysql.rds_kill(18003186);
CALL mysql.rds_kill(18122490);There is an AWS docs page on this too.
How to automatically kill long running queries in MySQL
It is all well and good to reactively kill stuck queries, but what if you could automatically kill them? This sounds far more ideal.
Looking at the parameters you can tune in MySQL, the one I will focus on is called max_execution_time.
From the official MySQL docs:
TheMAX_EXECUTION_TIMEhint is permitted only forSELECTstatements. It places a limitN(a timeout value in milliseconds) on how long a statement is permitted to execute before the server terminates it:
Checking that AWS RDS supports this parameter (using awscli):
aws rds describe-db-parameters --db-parameter-group-name $PARAMETER_GROUP_NAME | jq '.Parameters[] | select(.ParameterName == "max_execution_time")'and the resulting JSON output:
{
"ParameterName": "max_execution_time",
"Description": "The execution timeout for SELECT statements, in milliseconds.",
"Source": "engine-default",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "0-18446744073709551615",
"IsModifiable": true,
"ApplyMethod": "pending-reboot"
}So AWS RDS does support this parameter, and it's ApplyType is set to dynamic. This which means any changes are applied immediately (whereas static parameters require a database reboot to take effect).
Changing this parameter can be done via awscli or the UI. Here is a screenshot from the UI of the change we ended up making:
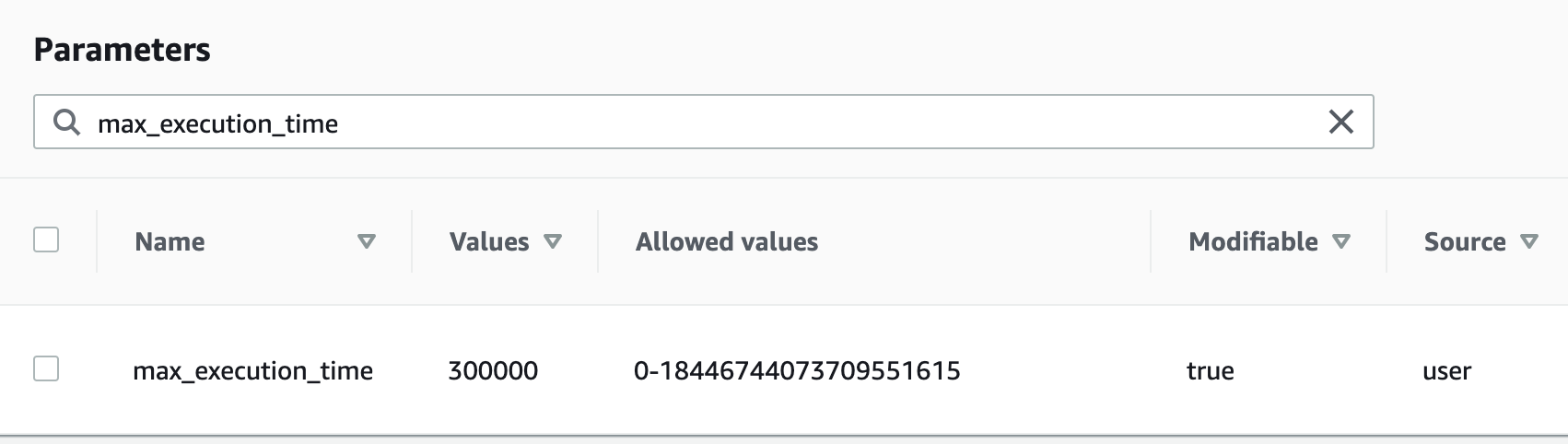
Note the value is in milliseconds, so 300 seconds is 300,000 milliseconds. For our applications, 5 minutes represents a huge amount of time, and no real query should be anywhere near this.
Proof it works
The simplest way to produce a query that will last at least 300 seconds (without crafting some nasty join monster), is to use sleep.
SELECT sleep(350);
Running this on the RDS server (as root), here you can see the query is 37 seconds into it's 350 second sleep:
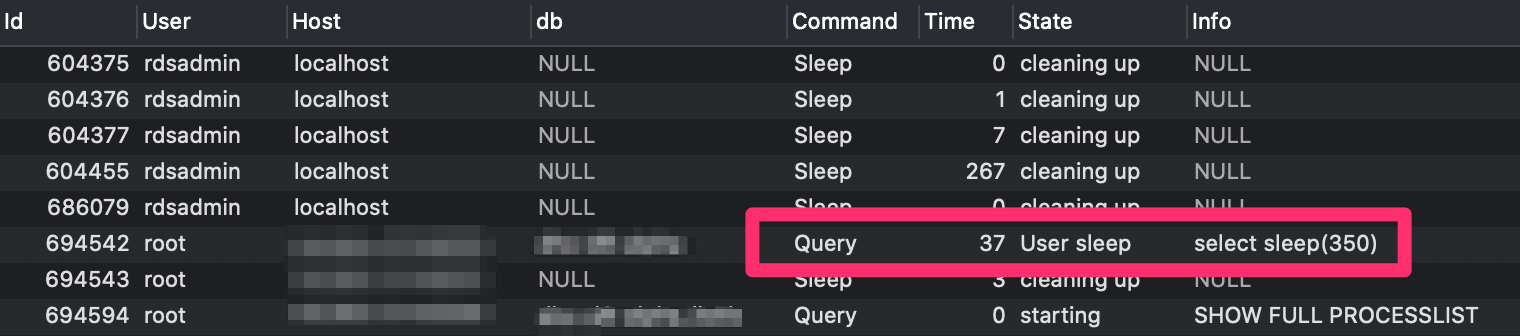
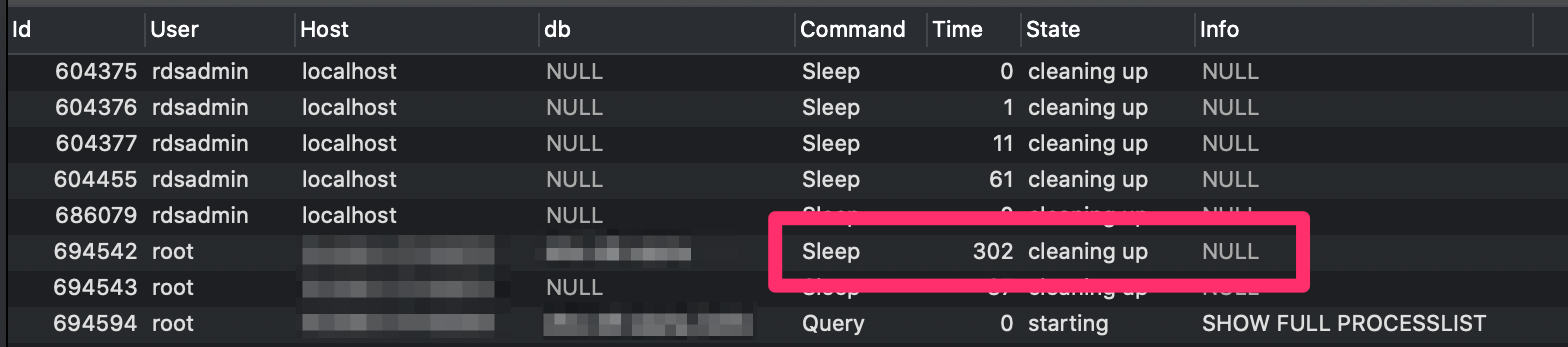
After the 300 second mark, the query's state moves to cleaning up, and will naturally die when the connection to the database dies.
Comments
We have been running this new parameter change on several large RDS clusters for a couple of weeks now, and have not seen any queries get stuck since, and no complaints from applications either. Let me know if this has helped you.