How computers see. A simple introduction to computer vision
Computers can’t actually see, but there are tools out there and methods for making computers “see” things we humans can.


Computers can’t actually see, but there are tools out there and methods for making computers “see” things we humans can. I’ve always been interested in this field but I found very little introductory information about the techniques involved. In this post, we’ll talk about some of the processes.
The centre component of all computer vision is images (with videos you work with a bunch of images). Normally you’ll be looking for something specific. Movement or objects of a particular colour or shape. These specific points of interest can be found but using certain techniques. You find points of interest by essentially removing data from the picture. What do I mean by “removing data”?
Since computers see images as millions of individual pixels each with colour and alpha values it’s difficult for a computer to determine if there are “things” in the image, so we remove data. Data is generally colours, and areas of the image that we know don’t contain any points of interest to us. We use methods like cropping, skewing and resizing to remove irrelevant areas of an image. We can also use techniques to remove the amount of colour to help make it easier for a computer to determine individual objects in an image.
Take this image of Waikiki beach for example.

In this image, if we wanted to count (roughly) how many people were in the lagoon. We could first crop out the sea beyond the sea wall and we could also crop out the beach. Since we aren’t interested in those areas.

That gives us a just the area we are concerned with.

Due to the perspective that the photo was taken, the people at the far end of the lagoon are slightly smaller than the ones closer to us, so we skew/warp the image so that the size of the people in the water are consistent at both ends of the lagoon.

Now to make it easier to count the people in the lagoon, we should remove some colour data.
One technique is to convert this image into a 2 colour black and white image. This process is called image binarization.
We do this because currently there are millions of different colour pixels in the image, and when a computer looks for points of interest in an image it will look for sections of similar colours and edges where the colours change. By converting this image to a 2 colour black and white image, finding individual sections of colours (white or black) and where the edges of such sections of colour is much easier. When we convert this image we will need to adjust the threshold so we still have the people in the lagoon.
Adjusting the threshold simply means choosing a point where any pixels lighter than this point will become white, and any pixels darker than will become black. Here is what the image looks like now.

You will, notice that some of the people now look really small, and some of the palm tree leaves/fronds are floating off on their own and a computer could potentially mistake these for people. We can use a process called dilation to help tidy this up. In this instance, this process essentially makes all the white pixels touching a black pixel also black. Making our blocks of black pixels bigger. We then end up with something like the following.

You can see that the palm fronds are now touching the base of the palm trees. We use dilate and it’s opposite erosion (Eroding an image will make each black pixel touching a white pixel, white) to tidy up images, and remove noise to make it easier to find things in an image. Sometimes we have to use a combination of the two or even dilate or erode multiple times to make the image easier to work with. I’m going to dilate the image again and also invert it.

Now we have an image that has a bunch of individual white blobs floating around on a black background. There are simple algorithms that a computer can use to easily find these points. This process is called, Blob detection I inverted the image because the tools I am used to using are good at finding light blobs on darker backgrounds, however this is not always the case. It will find all the points of interest that are separate from each other. You can see all these blobs outlined in green below.
Note: At this point you could count the people manually. However if this was a video feed, counting these blobs manually for every frame could be difficult. So we use libraries and function provided. If you wanted to implement your own, there are a ton of resources on the web for creating such methods.
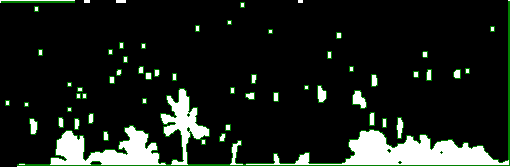
You’ll see that even the trees in the foreground are detected as blobs. Since wee are only concerned with people and (most) people aren’t as big as trees, we can make some assumptions about what blobs we are interested in. In the next image I ignored the largest blob, which is the largest consistent white mass, which in our case is the trees. We are left with the below.

We can use our library function to count how many blobs are detected. (now ignoring the trees). The number it gives me is 52. At this point, we could say that we can estimate of the number of people in the lagoon. 52 people.
However, looking at the image, there are a some things we could improve on.
You may notice, that there is a section at the top left that is highlighted in green. It’s actually part of the wall. We could easily eliminate that by being more careful then we were cropping the lagoon.
Also, if you compare the blobs image to the original one, you will notice that some of the people blobs are connected to the trees. These are ignored because we ignored the trees, to fix this we could play around with the threshold levels during the binarization or use dilation and erosion to adjust the image further.
Lastly, some of the bigger blobs are actually more than one person. A possible way to fix this would be to iterate over the blobs, figure out the average blob size per person, and if a large blob is detected, we could work out how many average sized blobs it could contain. We could even attempt to determine this based on shape. Below is the same image but fixed up a bit to take into account some of the points I just made.

In this image there are 62 blobs. We can now more accurately estimate the number of people in the lagoon. Manually counting the number of people in the lagoon from the original image, I came up with a higher number than 62, however with more tweaking we could get closer. If we had moving video footage we could get it right on the money. In fact, there are a number of ways to more accurately help computers see. A lot of the time it depends on the image or video. Time of day, lighting, position of camera and/or location of whatever we are trying to observe. Usually you’ll have to play around for a bit to get the right balance of adjustments needed to achieve your goal with the data you have available.
This has been a basic and crude example. It doesn’t have much practical use. Though, you could imagine if the photo was a fixed position web camera, you could write an app that could tweet people how many people are in the lagoon. Or how many people are outside the lagoon, perhaps surfing the break. Then you could know when was a less crowded time to go out for a surf. Who knows.
Most computer vision libraries make doing most of the processes mentioned above really easy. In future posts I’ll go over some of the tools and libraries you can use and even look at motion detection, and measuring sizes and speed. Eventually you’ll be able to make your computer become self aware. Well, not really. Yet.
Post in the comments if you want me to discuss anything specific.