Fastly Logging to Amazon S3 in JSON format
One of the cheapest and easiest methods for logging in Fastly is to use Amazon S3. This post will examine how to set this logging up, some of the common gotchas I came across after running this in production for a while now.


One of the cheapest and easiest methods for logging in Fastly is to use Amazon S3. S3 is extremely low cost, and suitable for long term storage and archival of logs.
This post will examine how to set this logging up, some of the common gotchas I came across after running this in production for a while now. The post will also explore how to download and analyse the logs.
Create a new logging endpoint
In the desired service, visit the Logging section, and add a new Amazon S3 endpoint.

Creating a custom JSON log format
Fastly comes with a default, I choose to log specific fields that are useful for debugging and analysis later.
{ "timestamp":%{time.start.sec}V, "service_id":"%{req.service_id}V", "time_elapsed":%{time.elapsed.usec}V, "is_edge":%{if(fastly.ff.visits_this_service == 0, "true", "false")}V, "client_ip":"%{req.http.Fastly-Client-IP}V", "client_as":"%{if(client.as.number!=0, client.as.number, "null")}V", "geo_city":"%{client.geo.city}V", "geo_country_code":"%{client.geo.country_code}V", "request":"%{req.request}V", "host":"%{json.escape(req.http.Host)}V", "url":"%{json.escape(req.url)}V", "request_referer":"%{json.escape(req.http.Referer)}V", "request_user_agent":"%{json.escape(req.http.User-Agent)}V", "resp_status":"%s", "resp_message":"%{resp.response}V", "resp_body_size":%{resp.body_bytes_written}V, "server_datacenter":"%{server.datacenter}V", "cache_status":"%{fastly_info.state}V", "waf_block":"%{req.http.X-Waf-Block}V", "waf_block_id":"%{req.http.X-Waf-Block-Id}V" }
An example request will look like this:
{
"timestamp": 1629796513,
"service_id": "4gJgt7cCs3QChTi2evKdke",
"time_elapsed": 1064614,
"is_edge": true,
"client_ip": "107.170.227.23",
"client_as": "14061",
"geo_city": "san francisco",
"geo_country_code": "US",
"request": "GET",
"host": "www.example.com",
"url": "/",
"request_referer": "http://www.example.com/",
"request_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36",
"resp_status": "200",
"resp_message": "OK",
"resp_body_size": 16362,
"server_datacenter": "PAO",
"cache_status": "MISS-CLUSTER",
"waf_block": "0",
"waf_block_id": "0"
}Extending the format
You can log pretty much anything you want here, there is a comprehensive list in the Fastly docs about other variables you can log.
Gotchas
During the development of our logging format several things have cropped up that I have had to solve:
Duplicate logs with shielding
If you enable shielding, then every request from an end user could potentially be 2 logs (edge PoP and shield PoP). In order to counter this, you can filter logs by is_edge being true. The below jq examples will show how to do this.
Escape user supplied fields
If you find this out the hard way when your JSON is no longer valid. An easy rule of thumb is - if it is supplied by the end user, then you must escape it
"host":"%{json.escape(req.http.Host)}V"Host header is supplied by the user, and thus must be escapedTruncate user supplied fields
I also saw examples where the user agent supplied was thousands of characters long, the same with the referrer. Fastly has some hidden truncation logic of it's own (around 1,500 characters or something), so the full log line will not be written. The solution was to deploy this VCL snippet in vcl_recv:
if ( req.http.request_referer ~ ".{1000,}" ) {
set req.http.request_referer = regsub(req.http.request_referer, "(.{0,125}).*", "\1");
}
if ( req.http.User-Agent ~ ".{1000,}" ) {
set req.http.User-Agent = regsub(req.http.User-Agent, "(.{0,125}).*", "\1");
}Set the S3 domain correctly
Unless your S3 bucket is in us-east-1 it is likely you will need to customise the domain for the S3 bucket. Ensure this is correct, else you will not see a single

s3.ap-southeast-2.amazonaws.com is the domain for S3 buckets in SydneyLog line format should be blank
This is now the default (it was not a while back), just ensure this stays on Blank, else Fastly will write 'helpful' timestamps to each line, and mess up the JSON syntax.
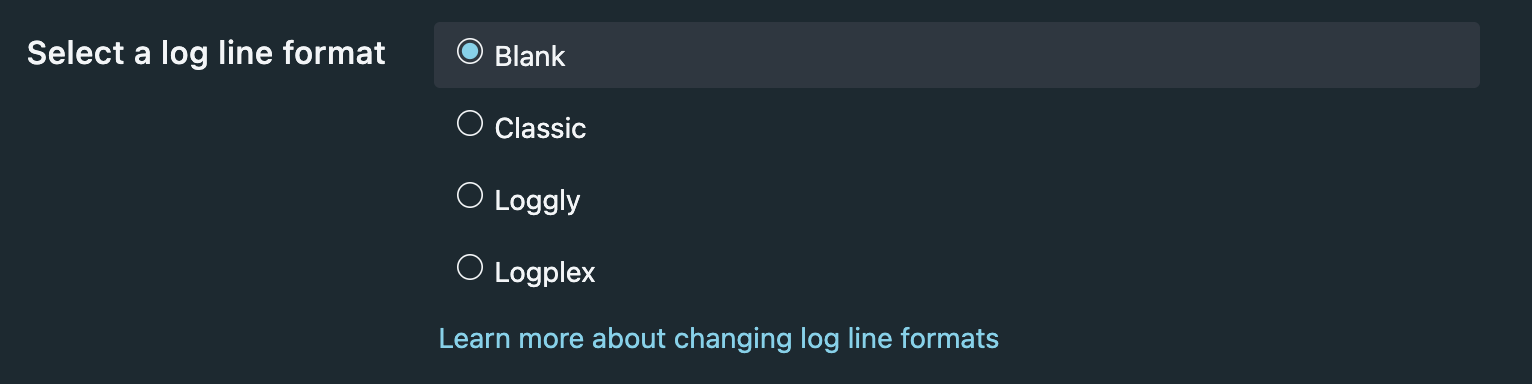
blank to ensure JSON logs stay JSONDownloading the logs
Now that logs are flowing into your S3 bucket, if you actually want to interact with them, it is likely better to download them. This is simple with the AWS CLI:
aws --profile PROFILE_NAME s3 sync s3://BUCKET_NAME/ . --exclude '*' --include '2021-09-25*'
This will produce a lot of log files (1 per PoP per hour). In order to do analysis on them, it is easier to have a giant log file:
find . -maxdepth 1 -name "*.log" -print0 | xargs -0 cat > logs.jsonAnalyse your Fastly logs
Now that you have the raw data, you should look to turn it into something you can make business decisions with.
Here are some simple analysis you can do with the jq tool (ensure you install this first if you have not already).
Top URIs
jq -r 'select(.is_edge) | .url' ${FILENAME} | sort -n | uniq -c | sort -nr | head -n 3
704990 /
670605 /sitewide_alert/load
109435 /ajax/site_alertTop user agents
jq -r 'select(.is_edge) | .request_user_agent' ${FILENAME} | sort -n | uniq -c | sort -nr | head -n 3
580342 Elastic-Heartbeat/7.14.0
418879 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36
290797 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36Top HTTP 404s
jq 'select(.is_edge and (.resp_status == "404")) | "\(.host)\(.url)"' ${FILENAME} | sort -n | uniq -c | sort -nr | head -n 3
58791 "www.example.com/sites/default/files/logo.png"
58117 "www.example.com/sites/default/files/social/Facebook.png"
58021 "www.example.com/sites/default/files/social/LinkedIn.png"Comments
If you have any neat tips and tricks around logging with Fastly to S3, please let me know in the comments.